
I currently hold a nirvana fallacy that the tempdb databases in our SQL Server instances can be set to an ideal maximum file size. This is a file size just large enough so that it won’t exceed the size of the volume with maybe 5GB to spare. A nirvana fallacy is “the informal fallacy of comparing actual things with unrealistic, idealized alternatives.”
It’s idealistic to believe that I can calculate an ideal maximum tempdb size. If I set a maximum size today, almost certainly it may be too large for the future. What follows is a work around process I recently set up to get the tempdb maximum size within limits and monitor it’s maximum potential file size on an ongoing basis for 18 instances (with as many Nirvana quotes that come as they are :-).
Has it always been a nirvana fallacy?
No, shrinking volume counts have lead to this. After several years of VMWare-based server evolution the number of volumes we set aside for SQL Servers keeps decreasing. I almost miss the days of fine tuning expensive RAID arrays for peak performance. On the physical servers I would use separate volumes for O/S, ETL, data, transaction logs, backup, indexes and tempdb. Lately I’m forced to use a just-in-time approach to storage size, and share tempdb with either the data drives or the backup drives. Since the free space on these drives fluctuates, the perfect solution to this problem is never attainable. But even though it’s unrealistic I’m compelled to live out this fallacy – to try to reduce the probability of full drives, since the cleanup on production systems is an ugly process.
Why pursue a nirvana fallacy?
So why am I seeking an idealistic solution? Earlier this month a coworker ran a multi-billion row query with an inferred cross apply in the query plan. PRTG alerted us to the impending drive failure as it was happening, and sp_whoisactive located the source of the query.
I looked at the tempdb_allocations for the query. It was (12,895,680 pages * 8K) = 105,641,410,560 bytes which was the same as the sum of all the tempdb files. After cleaning up the mess, the developer and I sat down to experiment with the execution plan. We found that duplicates in the join predicates on both sides of the results lead the optimizer to choose a many-to-many merge join, and rows were being sorted in a worktable in tempdb.
A few days later another developer ran a different runaway query in development with the same result. The developer said that in their last job they would just reboot the dev server. ::facepalm::. My idealistic alternative plan was to keep tempdb “locked inside a heart shaped box for weeks“. Well, maybe at least for one week.
Starting point – a nirvana fallacy spreadsheet.
I started with a spreadsheet for my initial experiments on the first servers. The spreadsheet looked like this:
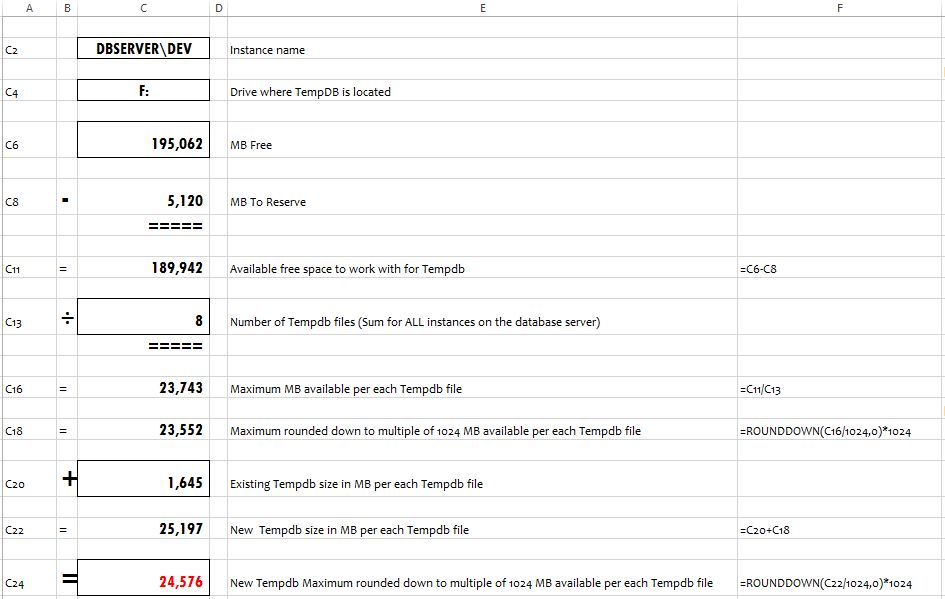
The spreadsheet is also on github. To come up with the calculations I needed a few queries on system tables, so I started with a few basic queries in my toolkit. As I was working with the spreadsheet I also pasted the source queries into in the xlsx file just in case I might never get around to automating the process.
After I ran the calculations on a few servers I was able to tweak the queries to get the results I needed from them, so I started to automate the process for the remaining servers.
Ending point – a nirvana fallacy stored procedure.
The final result is a stored procedure called sp_maxsize_tempdb(). The calculations are pretty simple. It runs the same calculations as all the queries from the spreadsheet and at the end generates the recommended ALTER DATABASE commands.
I’ve designed it as a CRUD procedure. A default @Action of ‘RECOMMEND’ will just calculate recommendations. If I use a bolder @Action of ‘ALTER’ it will actually alter the tempdb database. Note, since this is all a nirvana fallacy, we should probably call it a GRUNGE procedure instead of CRUD procedure. (I wish I could tell you how I *really* feel about CRUD procedures.) I’m not sure an ‘ALTER’ @Action is such a good idea. But I’ll take all the blame for what this might do? “I’ll take all the blame / Aqua seafoam shame”
The code for sp_maxsize_tempdb() is here on Github. It’s an early work in progress at this time. The stored procedure basically does what I expect it to do, and the PowerShell wrapper should be done soon.
The results look like this:
serverwide tempfiles are all on this instance: false (Warning! We need to count the tempfiles on all instances.) MIN MB Free this month: 5282.0 <-- Use this AVG MB Free this month: 8048.8 MAX MB Free this month: 11013.0 (4 rows affected) (4 rows affected) LogicalFileName ---------------------------------------- tempdev temp2 temp3 temp4 (4 rows affected) @MaxAvailablePerTempFile: 20.3 @RecommendedNewSize: 2824.0 @RecommendedNewSizeRounded: 3072.0 Here are the recommendations: ------------------------------------------------------------------------------------------------------------------------ alter database [tempdb] modify file (NAME = N'tempdev', MAXSIZE = 3072.0) alter database [tempdb] modify file (NAME = N'temp2', MAXSIZE = 3072.0) alter database [tempdb] modify file (NAME = N'temp3', MAXSIZE = 3072.0) alter database [tempdb] modify file (NAME = N'temp4', MAXSIZE = 3072.0) (4 rows affected)
It’s also an ugly script, but that’s ok. “I’m so happy ’cause today I found my friends / I’m so ugly, that’s okay, ’cause so are you”
The code is probably too localized to be easily used by anyone else without a lot of prep work. It has two dependencies that narrow its usability.
Dependency #1 – The sp_maxsize_tempdb() stored procedure needs to run on a dba management instance with a centralized sp_Blitz repository table. I don’t think too many people take advantage of this. My stored procedure uses the sp_Blitz table to look at the trend on the available disk space.
Dependency #2 – The sp_maxsize_tempdb() stored procedure takes advantage of a dba management instance with linked server connections to the target servers. I know linked servers aren’t a recommended practice, but makes it easy to check multiple instances from the same management instance as the centralized sp_Blitz repository table.
With this procedure I hope to appease my nirvana fallacy … to accurately monitor and control tempdb overgrowth. Hopefully, tempdb overflows will be an old memory … “as an old memoria”
Memoria.
All Nirvana puns aside, next week we’ll be staying at an Airbnb in Seattle very near Viretta Park, coincidentally on Kurt’s 25th anniversary vigil. Not sure if Viretta will be a somber place on Friday. If you have a favorite lyric for the park, let me know.
Update.
I’ve been told that the Spotify URLs on this page only link to the correct songs on the albums with a premium Spotify account. My apologies. By the way, Viretta Park was incredible.

