
I currently hold a nirvana fallacy that the tempdb databases in our SQL Server instances can be set to an ideal maximum file size. This is a file size just large enough so that it won’t exceed the size of the volume with maybe 5GB to spare. A nirvana fallacy is “the informal fallacy of comparing actual things with unrealistic, idealized alternatives.” Continue reading “An ideal tempdb is a nirvana fallacy.”
Msg 3180, a d’oh error.
I get pretty excited when I encounter a SQL Server error that I’ve never seen before. Today it was Msg 3180 during a point-in-time restore.
Msg 3180, Level 16, State 1, Line 2 This backup cannot be restored using WITH STANDBY because a database upgrade is needed. Reissue the RESTORE without WITH STANDBY. Msg 3013, Level 16, State 1, Line 2 RESTORE DATABASE is terminating abnormally.
Some background… About every two weeks we need to run a point-in-time restore to sync up with a timestamp on a loosely connected DB2 database on one of three different non-production systems.
These are tedious, and with a few exceptions are pretty repeatable processes.
My first sign that something was different came right after the initial WITH NORECOVERY restore. I was expecting to see the chain of ‘upgrade step’ messages following a recovery to a newer SQL Server platform.
Continue reading “Msg 3180, a d’oh error.”
Automatic documentation, Redgate SQL Doc and PowerShell.
Automatic writing … it turns out that’s really a thing. But unlike the ghostly last chapters of Dickens’s unfinished last novel, there’s no paranormal stuff going on in the PowerShell automation script I wrote this week.

Continue reading “Automatic documentation, Redgate SQL Doc and PowerShell.”
Are you sure? Last good DBCC CHECKDB over 2 weeks old.
So this past week I had a little confusion over a new CheckID that was suddenly firing every day in sp_Blitz. This new CheckId was number 68, ‘Last good DBCC CHECKDB over 2 weeks old.’ What? How could that be? I run it daily from Ola’s maintenance plans.
My first check was to verify if it was a recent occurrence only:
SELECT * FROM dbo.BlitzResults WHERE CheckID = 68;
Yup, in my history of BlitzResults it had only happened in the past day. So I kept looking since this was something new and weird.
Next check … were there errors in the Agent log for the dbcc script? No, nothing there, even though the agent truncates the script output anyway making that log fairly useless.
Next, check Ola’s log table. Clear. There were no errors in the maintenance plan logs for any DBCC_CHECKDB runs for the unit_test_1 database over its entire history.
SELECT * FROM [dbo].[CommandLog] WHERE CommandType = 'DBCC_CHECKDB' AND DatabaseName = 'unit_test_1';
Something was fishy, but was it a red herring?

Continue reading “Are you sure? Last good DBCC CHECKDB over 2 weeks old.”
The Silence of the Plan Cache Purge
I’m going to have to blog very quietly tonight since I don’t want the plan cache to hear me. This is a summary of a very silent plan cache purge on a production SQL Server that was whispering to us that it needed a new RAM configuration.
This purge was happening on an old SQL Server 2012 instance that I inherited from a contractor. It didn’t have all the settings that I put in my builds, especially for memory. On my new builds I follow Glenn Berry’s formulas for setting ‘max server memory (MB)’. see here (for general formula) or also here (see step 26.g)
Silent Rumors!
A colleague and I first discovered the silent purge when talking very quietly about a stored procedure that was just run three weeks prior and only runs once a year. We were talking very quietly since there were rumors floating around. Other coworkers were whispering that someone may have run the annual procedure more than once … scandalous! The first place I went to look for proof of the rumor was at the last_execution_time in sys.dm_exec_procedure_stats. You can imagine my horror when I found out that the plan cache had silently been purged the day before. I wanted to scream, but the plan cache may have heard me if I had done that.
Why the Silence?
Automating another SQL Server auditing script.
Introduction.
In today’s blog post I’m leveraging the work of another SQL Server MVP, Jason Brimhall. This summer Jason contributed a blog post to the July session of TSQL Tuesday. TSQL Tuesday is “a monthly blog party on the second Tuesday of each month”
::fn_trace_gettable
In Jason’s July blog, http://jasonbrimhall.info/2018/07/10/just-cant-cut-that-cord/, he presented an elegant script for detecting audit events from the default trace log. This fit in perfectly with the auditing theme that’s preoccupied much of my time this summer. So, I set out to automate it in Powershell so that I could drive the automation from any server using my typical Powershell coding approach.
This turned out to be pretty easy…
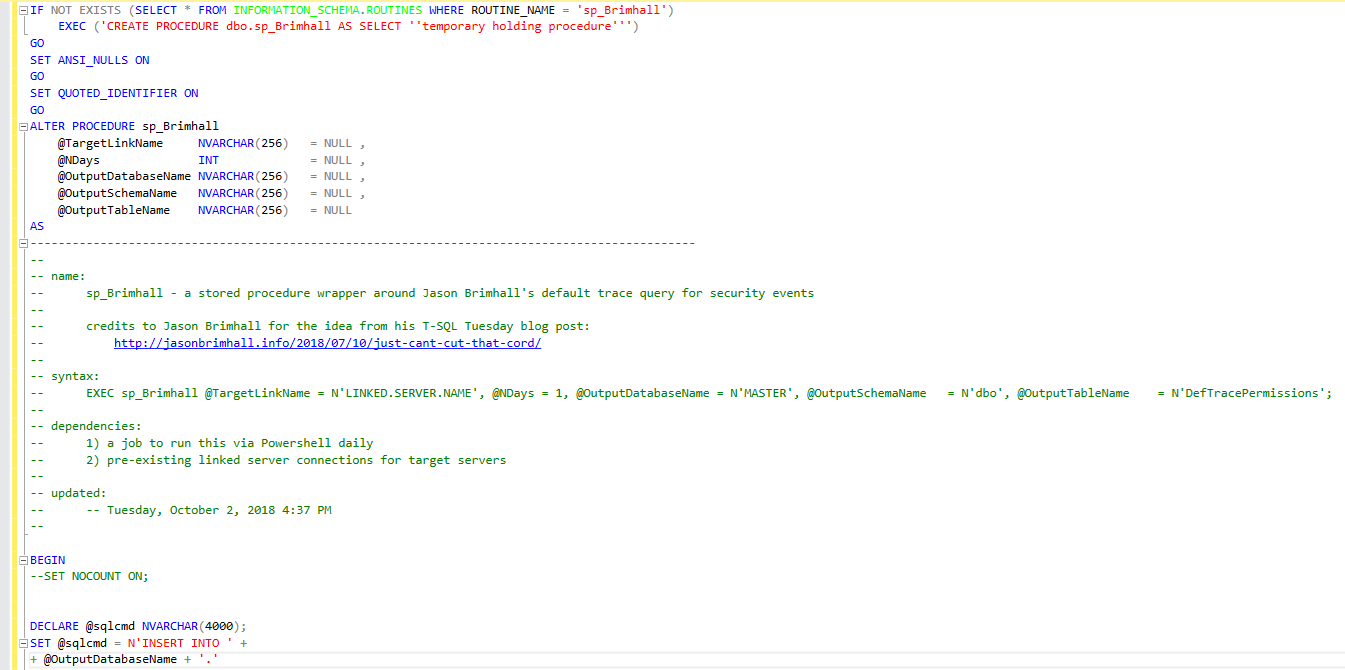
Continue reading “Automating another SQL Server auditing script.”
Automation of sp_Blitz with a PowerShell wrapper
Introduction to sp_Blitz
This summer I’ve had several pressing reasons for automating Brent Ozar’s sp_Blitz, a popular SQL Server database health check script that is part of the BrentOzarULTD/SQL-Server-
The ISACA
One of my reasons for automating is to help with the ISACA www.isaca.org database audit assurance program. Many of the questions tie directly to areas that sp_Blitz is checking.
For example, ISACA question number 3.1.1.2, can be answered with this query:
Continue reading “Automation of sp_Blitz with a PowerShell wrapper “
JMeter, SQL Server and Thread Safety.
It’s been a busy summer and I’ve missed making a lot of posts. This post is about an interesting event from June — interesting from a technical point of view, but also because it highlights a testing trap that I fall into repeatedly, which is reporting errors from tests that are slightly out of scale.
Using Apache JMeter for SQL Server concurrency testing.
I’ve used Apache JMeter in the past for stress testing J2EE web apps. Vendors don’t like me very much when I tell them we’re going to run a stress test on their apps. Oh, and if your network group is paranoid you may need to reassure them that you have mission-critical testing requirements before you start using JMeter. This time around I’m using it as a shell around a SQL script for calling a stored procedure that I strongly suspected of concurrency issues.
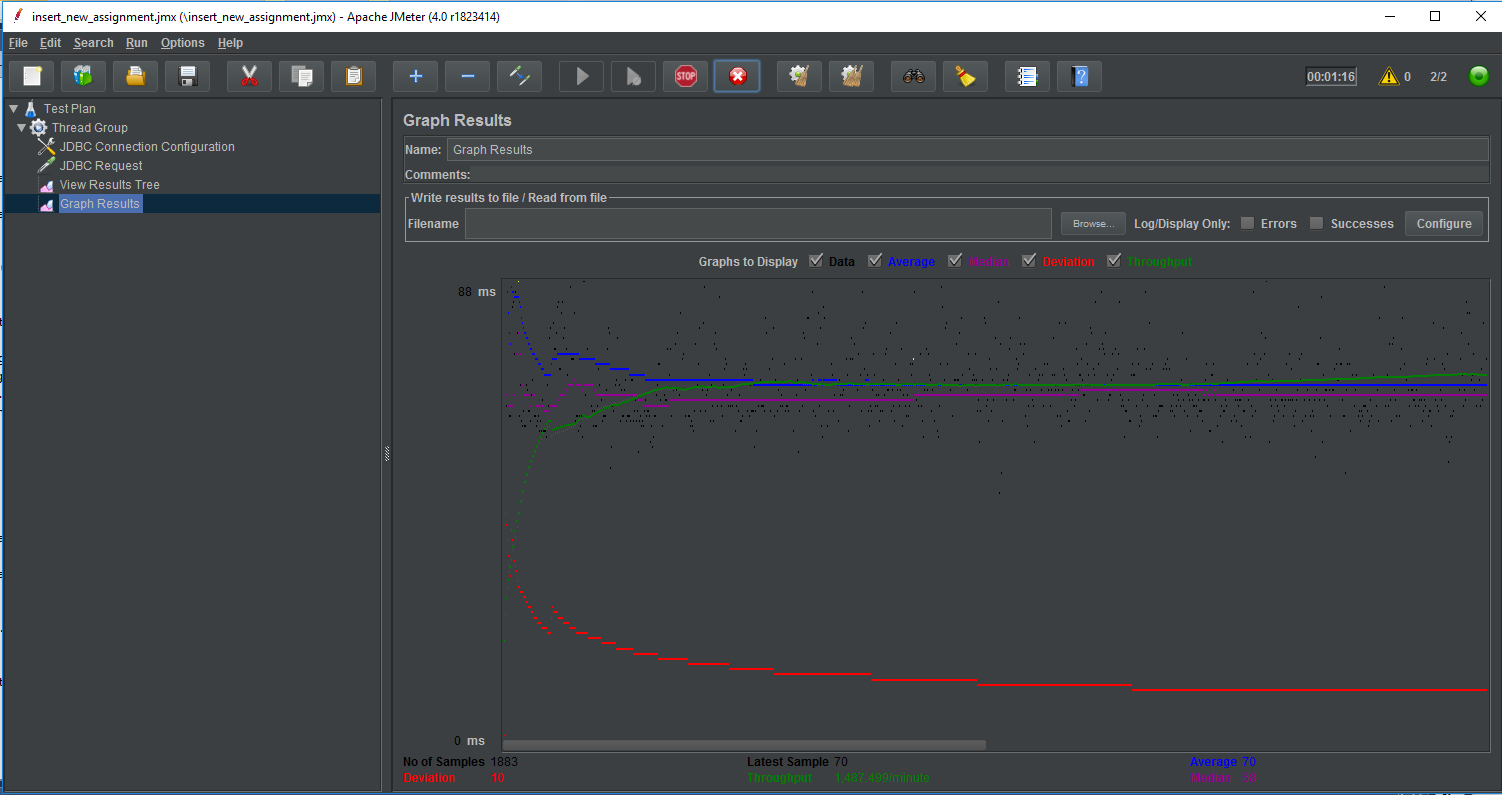
Continue reading “JMeter, SQL Server and Thread Safety.”